功能描述:
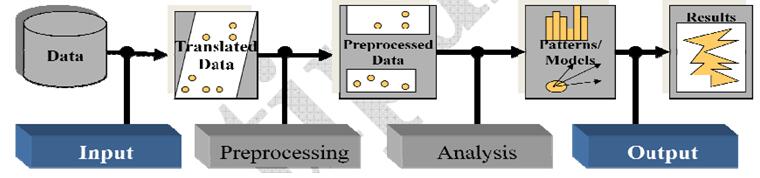
分析流程如下所示,根据本课题的数据以及所需要的结果形式,其结果符合要求的为1,不符合的为空,这里我们将不符合数据的定义为0,那么整个系统其实可以等效为一个分类算法,即通过数据挖掘进行分类,即符合需求类1和不符合需求类0,基于这个思路进行设计。
一般数据挖掘算法流程如下所示:
第一步,建立模型,确定数据表中哪些列是要用于输入,哪些是用于预测,选择用何种算法。这时建立的模型内容是空的,在模型没有经过训练之前,计算机是无法知道如何分类数据的。
第二步,准备模型数据集,例子中的模型数据集就是1000个会员数据。通常的做法是将模型集分成训练集和检验集,比如从1000个会员数据中随机抽取700个作为训练集,剩下300个作为检验集。
第三步,用训练数据集填充模型,这个过程是对模型进行训练,模型训练后就有分类的内容了,像例子图中的树状结构那样,然后模型就可以对新加入的会员事例进行分类了。比如前两年的数据训练之后预测第三年的,当进入第四年的时候,使用第二年和第三年的数据进行训练,从而不断的更新模型。
第四步,使用模型对预测集进行预测。
整个算法的理论如下所示:
首先,我们需要建立的是一个函数f,该函数满足如下的需求:

其中f可以是一个数学公式,也可以是一个抽象的网络。这里,根据各种实战经验,一般对于复杂的情况,一般最后得到的函数f为一个抽象的网络。
决策树是一树状结构,它从根节点开始,对数据样本进行测试,根据不同的结果将数据样本划分成不同的数据样本子集,每个数据样本子集构成一子节点。生成的决策树每个叶节点对应一个分类。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。
根据决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
决策树方法中分类的目的是分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。由此生成的类描述用来对未来的测试数据进行分类。尽管这些未来的测试数据的类标签是未知的,我们仍可以由此预测这些新数据所属的类。我们也可以由此对数据中的每一个类有更好的理解。或者说我们获得了对这个类的知识。
构造一个决策树通常分为两步:树的生成和剪枝。
决策树的生成是一个从上至下,是一个递归的过程。设数据样本集S,算法框为如果数据样本集S中所有样本都属于同一类或者满足其它终止准则, 则S不再划分,形成叶节点;否则,根据某种策略选择一个属性,按照属性的各个取值对S进行划分,得到n个子样本集,记为Si。再对每个Si迭代执行步骤1。经过n 次递归, 最后生成决策树。从根到叶结点的一条路径就对应着一条规则, 整棵决策树就对应着一组析取表达式规则。树构成步骤中, 主要就是找出节点的属性和如何对属性值进行划分。
决策树生成后面临的问题是树的过度细化,特别是存在噪声数据或不规范属性时更为突出,决策树的修剪就是对过度细化的模型进行调整。修剪算法分为前剪枝算法和后剪枝算法两种。前剪枝算法是在树的生长过程完成前就进行剪枝。这类算法的优点是在树的生长同时就进行了剪枝,因而效率高,但是它可能剪去了某些有用但还没有生成的节点。后剪枝算法是当决策树的生长过程完成后再进行剪枝。它分为需要单独剪枝集和不需要单独剪枝集两种情况。后剪枝有一些优点,例如,当单个的两个属性似乎没什么用处,但当结合在一起时却有强大的预测能力,即一种结合效果,在两个属性值正确结合时是非常有用的,而单个属性则没有用。
联系:highspeedlogic
QQ :1224848052
微信:HuangL1121
邮箱:1224848052@qq.com
网站:http://www.mat7lab.com/
网站:http://www.hslogic.com/
|