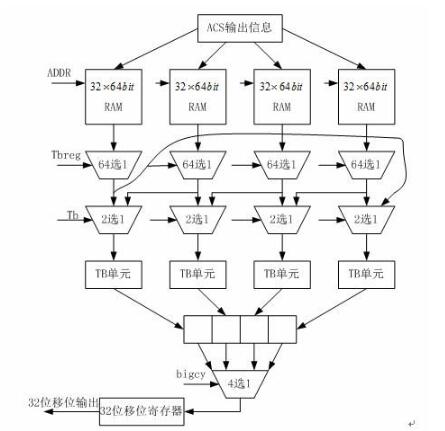
功能描述:
二:viterbi译码器
(2,1,7)卷积码译码过程的总体结构可分为4个子模块,分别是分支度量模块,加比选蝶形运算单元,幸存路径存储单元和回溯译码单元。
译码器的结构框图如图3所示。

・分支度量计算单元
分支度量计算单元是用来计算输入信号序列与卷积码各个可能输出信号序列的似然度量,维特比的似然准则就是在寻找具有最小距离的路径。若译码器采用硬判决译码时,分支度量计算采用汉明距离,而采用软判决译码时,则是采用欧氏距离,即计算

采用这种方法,与采用欧氏距离相比,对译码器的性能影响不大,该译码器的性能与采用欧氏距离的译码器性能差仅有0.1~0.2dB。
由上式可以看出,如果采用8电平量化软判决方式,则此时路径度量值扩展为0到14,所以分支度量单元的输入是3比特数据,而输出则是4比特数据,这样硬件实现比较简单,可以减少硬件开销。
其硬件实现电路结构如图4所示。由于本设计中采用的是(2,1,7)卷积码,所以一级中共有64个结点,需要64个分支度量计算单元,在实现中,采用了全并行的结构,这样在一个时钟周期内,可以更新所有64个结点的分支度量值。

图4 分支度量计算单元的硬件电路结构
其代码如下所示:

assign I = (en) ? Iin : 0; //软判决输出模块
assign Q = (en) ? Qin : 7; //软判决输出模块
assign recom = reset &en | start;
wire [3:0] bm0,bm1,bm2,bm3;
assign bm0=bm00(I,Q);//BM模块的输出
assign bm1=bm01(I,Q);//BM模块的输出
assign bm2=bm10(I,Q);//BM模块的输出
assign bm3=bm11(I,Q);//BM模块的输出
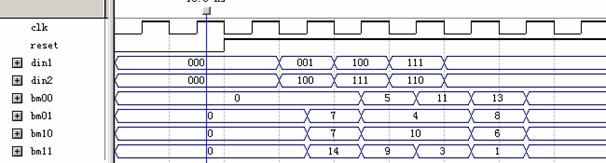
其仿真结果如下所示:
・加比选模块
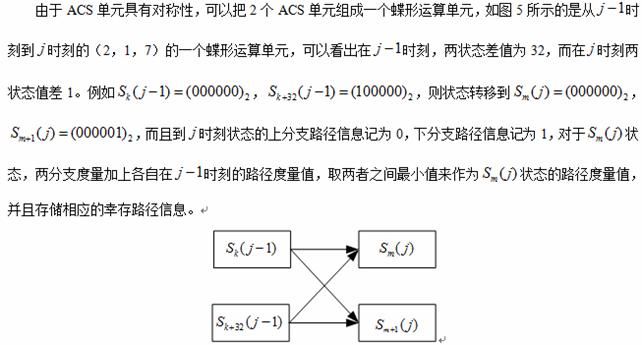
图5 ACS蝶形运算单元框图
通过对加比选过程的分析,可以发现每次分支度量值都是非负的,因此分支累计度量值是不断增加的,由于在硬件实现中不能不考虑分支累计度量值的位宽,因为在硬件实现时该值需要存储在有限位宽的寄存器,所以需要对累计度量值进行归一化运算,以防止在累加过程中发生数据溢出,常用的控制方法是在每一步运算后首先找出所有状态节点的累计度量值中最小的一个,最后要减去该最小值,这种方法的主要缺点是每次加比选运算后都要对更新后的累加结果进行大量的比较操作,以找出最小累计度量值并将其置0,其余累计度量值与该最小值相减后得到的结果存储下来,以供下一次加比选操作使用。维特比译码器的译码输出只与度量值的相对值有关,每一步的路径度量值的最大值与最小值满足下面的关系:

在本设计中采用补码加法运算方法可以自动完成归一化中的求模运算,其电路结构如图6所示,其中比较器电路结构如图7所示。

ACS模块的代码如下所示:
module ACS(
din_a, //BM模块
gama_a, //前一时刻64个状态的路径量度
din_b, //BM模块
gama_b, //前一时刻64个状态的路径量度
gama_out,//路径量度输出
sel //幸存选择
);
input [3:0] din_a;
input [3:0] din_b;
input [7:0] gama_a;
input [7:0] gama_b;
output [7:0] gama_out;
output sel;
wire [7:0] m1,m2;
wire cmp;
wire flag;
assign m1=gama_a+{4'b0,din_a};
assign m2=gama_b+{4'b0,din_b};
assign cmp=(m1[6:0]>m2[6:0])?1:0;//比较选择
assign flag=m1[7]^m2[7];
assign sel=flag^cmp;
assign gama_out=(sel)?m2:m1;
endmodule
其中我们需要调用ACS模块64次。
ACS ACS_u1(
.din_a(bm1),
.gama_a(PM1),
.din_b(bm2),
.gama_b(PM33),
.gama_out(pp1),
.sel(sel1)
);
…………………………………..
ACS ACS_u64(
.din_a(bm1),
.gama_a(PM32),
.din_b(bm2),
.gama_b(PM64),
.gama_out(pp64),
.sel(sel64)
);
・幸存路径存储单元
(2,1,7)卷积码每向前译码一位要产生64位的幸存路径,所以我们用一个64位宽的RAM来存储ACS产生的幸存路径信息。在回溯的过程中,也就是从RAM中读出幸存路径值来决定回溯的路径。
//最小路径量度状态选择
assign survival={
sel1 ,sel2 ,sel3 ,sel4 ,sel5 ,sel6 ,sel7 ,sel8 ,sel9 ,sel10,sel11,sel12,sel13,sel14,sel15,
sel16,sel17,sel18,sel19,sel20,sel21,sel22,sel23,sel24,sel25,sel26,sel27,sel28,sel29,sel30,
sel31,sel32,sel33,sel34,sel35,sel36,sel37,sel38,sel39,sel40,sel41,sel42,sel43,sel44,sel45,
sel46,sel47,sel48,sel49,sel50,sel51,sel52,sel53,sel54,sel55,sel56,sel57,sel58,sel59,sel60,
sel61,sel62,sel63,sel64
};
・回溯译码单元
回溯译码单元是本设计的重点,其回溯单元框图如图8所示:
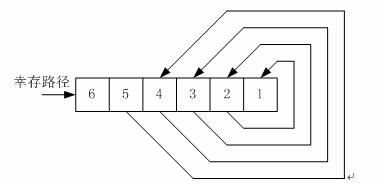
图8 回溯单元结构图
在本设计中回溯译码单元如图9,回溯译码共用4块32*64bit的RAM,在回溯译码单元有两个计数器,其中模32加法计数器产生RAM的写地址add32,模32减法计数器产生回溯过程中RAM的读地址sub32。
另外还有一个模4的计数器产生四块RAM的读写控制信号,当译码开始后,幸存路径首先存储在第一块RAM中,然后存储第二块RAM,当进行到第64个时钟周期时,第二块RAM存储完毕,然后开始存储第三块RAM,同时从第二块RAM中开始回溯,当运行到96个时钟周期时,第三块RAM存储完毕,第二块RAM也回溯完毕,然后开始存储第四块RAM,同时第一块RAM 开始回溯,这时回溯出的信息就是正确的信息,这样循环执行,可以保证四块RAM中有两块RAM在回溯过程中。

一块RAM在存储幸存路径。其中四块RAM的输出对应一个64选1的MUX,并且它的输出还要经过一个2选1的MUX选择输出,然后再输入到回溯单元,回溯单元通过一个简单的移位操作,回溯到前一个状态,回溯输出通过一个4选1的MUX选择输出的就是译码输出,并写入到32bit的寄存器中,每32时钟周期一次输出32bit的回溯信息结果,我们这里存储下32bit的回溯信息后,然后每个时钟周期输出一个比特的译码信息。在设计中卷积码的译码回溯深度最小为32,最大为64。
//幸存信息管理
sram sram_u1(
.address (add1),
.clock (clk),
.data (survival),
.wren (wen[0]),
.q (dout1)
);
sram sram_u2(
.address (add2),
.clock (clk),
.data (survival),
.wren (wen[1]),
.q (dout2)
);
sram sram_u3(
.address (add3),
.clock (clk),
.data (survival),
.wren (wen[2]),
.q (dout3)
);
sram sram_u4(
.address (add4),
.clock (clk),
.data (survival),
.wren (wen[3]),
.q (dout4)
);
reg val_out;
reg valid;
always @(posedge clk or negedge reset)
begin
if(!reset)
begin
val_out <= 0;
valid <= 0;
end
else
begin
val_out <= val;
valid <= val_out;
end
end
reg [2:0] count1;
always @(posedge clk or negedge reset)
begin
if(!reset)
count1 <= 0;
else if(val_out)
count1 <= count1 + 1;
else
count1 <= count1;
end
reg [2:0] count;
always @(posedge clk or negedge reset)
begin
if(!reset)
count <= 0;
else if(val_out)
begin
if((count<=3)&(count1==0))
count <= count + 1;
else if((count==4)&(count1==0))
count <= 1;
end
else
count <= count;
end
reg [31:0] decoke_out;
always @(posedge clk or negedge reset)
begin
if(!reset)
decoke_out <= 0;
else if((val_out)&(count==0)&(count1==0))
decoke_out <= decoke;
else if((val_out)&(count==4)&(count1==0))
decoke_out <= decoke;
else
decoke_out <= decoke_out;
end
function [7:0] dout;
input [31:0] dec;
input [2:0] sel;
begin
case(sel)
3'b001:dout=dec[31:24];
3'b010:dout=dec[23:16];
3'b011:dout=dec[15:8];
3'b100:dout=dec[7:0];
default:dout=0;
endcase
end
endfunction
assign dataout=val_out?dout(decoke_out,count):0;
联系:highspeedlogic
QQ :1224848052
微信:HuangL1121
邮箱:1224848052@qq.com
网站:http://www.mat7lab.com/
网站:http://www.hslogic.com/
微信扫一扫:

--------------------------------------------------------------------------------------
人工智能代做,深度学习代做,深度强化学习代做,zynq智能系统FPGA开发,
AI代做,卷积神经网络,Alexnet,GoogleNet,CNN,TensorFlow,
caffe,pointnet,PPO,Qlearning,FasterRCNN,MTCNN,
SPPNet,word2vec,SARASA算法,梯度策略等等